Develop Study/Middleware
(24.10.21) Message Queue 그리고 Redis
실제로 천 단위로 요청이 발생하는 스트리밍, 또는 실시간 대용량 데이터즉, 트래픽에 관해서
비동기 서비스를 사용해서 프로젝트를 진행하지도 못했고(높은 서비스 가격)
관련해서 많은 서비스가 존재하기 때문에,
관련 면접 질문, 또 인프라 관련 지식을 위해
알고 있는 비동기 서비스인 Redis와 비교도 하면서 가장 대표적인 3가지 Message Queue 비동기 서비스를 표로 정리를 했다.
메시지 큐 Message Queue
- 메시지는 어떠한 하나의 요청 을 말하는 것
- 평문 부터 여러 형태의 데이터를 Application간에 전달하는 것을 목적으로 하는 것
ex) JSON, XML, BinaryData(이미지, 파일, 객체 등), 등등
Apache Kafka
- 대용량 데이터 처리와 실시간 데이터 스트리밍을 위한 분산형 스트리밍 플랫폼, 메시지 큐 시스템
- 이벤트 기반 시스템
- 비동기 메시지 처리 기능
- 사용
- 로그 수집, 데이터 분석, 실시간 데이터 처리 등
구성
- 프로듀서(Producer)
- 메시지 생성 → **토픽(Topic)**에 전송 역할
- 로그 데이터 생성, 트랜잭션 처리, 사용자 활동 데이터(=메시지) 등 Kafka에 전달시 사용
- 토픽(Topic)
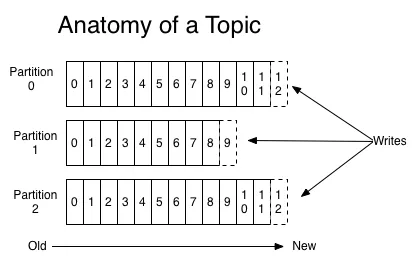
(출처 : https://kafka.apache.org/ )
- 데이터 스트림이 저장되는 논리적인 이름 공간
- 프로듀서가 보낸 데이터, 부할된 브로커의 파티션을를 컨슈머**(Consumer)**가 읽는 단위
- 컨슈머(Consumer)
- 메시지를 읽어오는 역할을 하는 클라이언트
- 메시지를 소비(Consume)할 때 커밋(Commit)을 사용하여 메시지의 오프셋(Offset)을 관리
- 여러 컨슈머가 협력하여 하나의 토픽에서 메시지를 동시에 처리가능
- 컨슈머(Consumer)
- 여러 파티션으로 분할되어서 구성
- 로그의 카테고리라고 생각할 수 있으며, 메시지의 저장 순서를 보장하는 데 사용
- 파티션(Partition)
- 토픽이 분할된 단위, 각 파티션은 독립된 순서로 메시지를 저장
- 메시지의 순서가 보장이나 전체 토픽 수준에서는 파티션별 순서 보장 X
- 병렬로 메시지를 처리하는 확장성
- 토픽이 분할된 단위, 각 파티션은 독립된 순서로 메시지를 저장
- 브로커(Broker)
- Kafka 서버의 인스턴스
- Kafka 클러스터는 여러 개의 브로커로 구성 / 각 브로커는 특정 파티션들을 관리
- 브로커가 많을수록 더 많은 파티션을 처리할 수 있어 클러스터의 확장성이 향상됩니다.
- 클러스터(Cluster)
- 여러 브로커가 모여 하나의 Kafka 클러스터를 구성
- 데이터의 복제 및 분산으로 데이터의 가용성과 내결함성 보장
주요 특징
대용량 데이터 처리
- 초당 수백만 건의 메시지를 처리할 수 있는 고성능 메시지 큐
- 대규모의 데이터 스트림을 효율적으로 처리에 최적화
디스크 기반 저장소
- 메시지를 디스크에 저장하여 데이터를 영구적으로 보관
- 데이터 손실을 방지, 다시 데이터를 읽을 수 있음
- 해당 디스크는 Kafka 서비스 서버의 물리적인 디스크
- 설정에 따라 보존 기간, 최대 저장 크기 설정 가능
확장성 및 분산 처리
- 파티셔닝과 브로커들로 분산 가능 → 클러스터를 손쉽게 확장
- 데이터의 분산 처리 및 병렬 처리가 가능하므로 대규모 트래픽 처리에 적합
내결함성 및 복제
- Kafka는 메시지를 복제하여 브로커 간에 저장함으로써 시스템 가용성 보장
- 브로커가 다운되더라도, 다른 복제본을 통해 데이터를 안전하게 복구할 수 있습니다.
순서 보장
- 단일 파티션 내에서는 메시지의 순서가 보장
- 키 기반의 파티셔닝으로 전체 글로벌 순서보장보다는 일부 순서를 보장하는 방식
- 글로벌 순서 보장을 한다면, 빠르게 병렬로 데이터를 처리할 수 없게 되어버림
- 이를 통해 순차적인 데이터 처리가 필요한 애플리케이션에서 유용하게 사용할 수 있습니다.
유연한 데이터 스트리밍
- 실시간 데이터 스트리밍과 배치 처리 모두에 사용
- 다양한 애플리케이션과 데이터 파이프라인 구축에 유연하게 대응
RabbitMQ
- AMQP (Advanced Message Queuing Protocol) 구현 오픈소스 메시징 큐 서비스
- 메시지 큐 방식으로 Application간 비동기 통신, 작업분배에 활용가능
- Kafka와 같이 메시지 브로커를 사용(AMQP)
AMQP (Advanced Message Queuing Protocol) 기반 메시징 프로토콜
- 메시지 지향 오픈 표준 프로토콜로, Application간 메시지로 통신, 시스템과의 독립적인 상호작용을 보장
- 비동기 작업 처리, 이벤트 기반의 아키텍쳐, 마이크로 서비스에서 사용이 가능
- 주요 특징
- 상호 운용성
- 다양한 프로그래밍 언어와 플랫폼에서 사용될 수 있도록 설계
- 서로 다른 시스템 간에 메시지를 쉽게 주고 받기 가능
- 메시지 브로커
- 메시지를 생성, 전송, 수신 및 저장하는 메시지 브로커와 함께 작동
- 브로커는 메시지의 라우팅과 보관을 담당
- 메시지 전달 보장
- 내구성(Durability) 설정을 통해 메시지가 손실되지 않고 브로커에 안전하게 저장
- 메시지 라우팅
- AMQP는 메시지를 **교환기(Exchange)**를 통해 큐로 라우팅
- 다양한 라우팅 전략(Direct, Topic, Fanout 등)을 제공하여 유연한 메시지 전달
- 비동기 처리
- AMQP는 비동기 메시징을 지원
- 프로듀서와 컨슈머가 독립적으로 작동 → 성능과 확장성 향상
- QoS(Quality of Service)
- AMQP는 메시지 전송 품질을 관리하는 여러 QoS 매개변수를 제공 → 메시지가 컨슈머에게 어떻게 전달되는지 제어
- Transactional Messaging
- AMQP는 트랜잭션 메시징을 지원하여, 여러 메시지를 원자적으로 처리할 수 있는 기능을 제공
- 상호 운용성
주요 특징
AMQP 기반의 메시징 프로토콜
- RabbitMQ는 AMQP를 기반으로 설계되어, 메시지 전송, 큐잉, 라우팅, 보안, 신뢰성 등을 제공하는 기능
- 다양한 라우팅 전략(Direct, Topic, Fanout, Headers)을 통해 메시지의 전달 경로를 유연하게 설정
메시지 큐를 통한 작업 분배
- 프로듀서(Producer)가 메시지를 큐(Queue)에 넣고, 컨슈머(Consumer)는 브로커가 배정한 큐에서 메시지를 소비하는 형식
- 여러 컨슈머가 하나의 큐를 공유 → 메시지를 분배해 병렬 처리를 가능, 작업을 효율적으로 분배
메시지 순서 보장
- 큐 단위로 메시지의 순서가 보장
- 큐에 들어간 순서대로 컨슈머가 메시지를 처리하므로, 순서가 중요한 작업에서 유리
- 이벤트 기반과는 다르게 메시지가 완료후 다음 메시지로 넘어가는 FIFO이기 때문에 순서를 보장
다양한 라우팅 옵션
- Direct Exchange: 특정 라우팅 키를 기준으로 메시지를 특정 큐에 전달
- Topic Exchange: 와일드카드 문자를 사용해 메시지를 다수의 큐에 전달
- Fanout Exchange: 모든 연결된 큐에 메시지를 브로드캐스트
- Headers Exchange: 메시지 헤더를 기반으로 라우팅
확장성 및 고가용성
- 클러스터링을 통한 메시지 브로커의 확장성을 제공, 고가용성(High Availability) 구현
- 여러 노드에 걸쳐 큐와 메시지 복제를 통해 데이터의 내결함성을 확보
- Apache Kafka의 파티션을 해당 RabbitMQ에서는 메시지 큐가 그 역할
메시지 신뢰성 보장
- Ack/Nack 메커니즘을 사용해 메시지가 정상적으로 처리되었는지 확인
- Ack/Nack 메커니즘
- Ack (Acknowledgment):
- 컨슈머가 메시지를 성공적으로 처리한 후, RabbitMQ에 확인 응답(ack)
- ack을 받으면 RabbitMQ는 해당 메시지를 큐에서 제거
- Nack (Negative Acknowledgment):
- 컨슈머가 메시지를 처리하지 못했거나, 오류가 발생한 경우 Nack을 RabbitMQ에 응답
- Nack을 보내면, RabbitMQ는 해당 메시지를 큐에 다시 추가 또는 다른 컨슈머에게 재분배
- Ack (Acknowledgment):
- Ack/Nack 메커니즘
- 메시지의 내구성(Durability)을 설정하여 서버가 재시작하더라도 메시지가 유실 방지
Amazon SQS, Simple Queue Service
- AWS 에서 제공하고 있는 완전관리형 메시지 큐 서비스
- 분산 시스템에서 메시지를 비동기로 전달 지원
주요 특징
완전관리형 서비스
- 사용자는 서버 및 인프라를 관리할 필요 없이 큐를 생성하고 사용
- AWS에서 인프라(인스턴스, 저장소, 네트워크 등)을 자체 여러 서비스로 운용해서 연계로 바로 쓸 수 있기 때문에
- 사용자는 큐의 수/타입 만 결정해서 생성만 하면 됨 (아래 참고)
- 큐의 관리(스케일링, 복구, CloudWatch를 통한 모니터링, 메트릭 수집 등)도 AWS가 자동으로 처리
비동기 메시지 전송
- 메시지를 보낸 후 즉시 응답을 기다릴 필요 없이 다른 작업을 수행
- 시스템의 확장성과 유연성
FIFO 및 표준 큐
- SQS는 두 가지 유형의 큐를 제공합니다:
- 표준 큐: 높은 처리량을 제공하지만 메시지의 순서가 보장되지 않으며, 중복 메시지가 발생 가능성
- FIFO 큐: 메시지의 순서가 보장, 중복 메시지가 발생X,낮은 처리량
높은 가용성과 내결함성
- 메시지는 여러 가용 영역(리전)에 저장되며, 장애 발생 시에도 안전하게 복구
확장성
- SQS는 수천 개의 메시지를 동시에 처리할 수 있으며, 트래픽이 증가하더라도 자동으로 확장
- 사용자는 처리량에 대한 걱정 없이 서비스를 확장 설정이 가능
- 컨슈머의 수를 늘리거나 큐의 길이를 짧게하여 대기 메시지를 줄이는 방법 등
보안
- SQS는 IAM(Identity and Access Management)을 사용하여 큐에 대한 접근을 제어할 수 있으며, 메시지를 암호화하여 보안성을 확보가 가능
Dead Letter Queue (DLQ)
- 처리할 수 없는 메시지를 별도의 큐로 이동시키는 기능
- 실패한 메시지를 추적하고 분석, 시스템의 신뢰성을 높일 수 있습니다.
Message Queue vs Redis
메시지 큐 기술 비교
| 특성 | Kafka | RabbitMQ | Amazon SQS | Redis |
| 주요 사용 사례 | 실시간 로그 수집, 이벤트 스트리밍, 데이터 파이프라인 구축 | 작업 분배, 알림 시스템, 금융 거래 처리 | 백오피스 작업 큐, 이메일 전송 대기열, 비동기 데이터 처리 | 캐싱, 세션 관리, 실시간 데이터 업데이트, 분산 락 |
| 주요 특징 | - 대량의 데이터 처리에 적합 - 파티션 기반 데이터 저장 - 높은 내구성과 복원력 |
- 다양한 메시지 라우팅 옵션 (Fanout, Topic 등) - 여러 프로토콜 지원 - 신뢰성 있는 메시지 전송 |
- 완전 관리형 - 표준 큐와 FIFO 큐 지원 - 자동 확장 가능 |
- 메모리 기반 처리 속도 - 단순한 데이터 구조 지원 - Pub/Sub 모델 지원 |
| 기반 저장소 | 디스크 기반 (로그 파일 형태로 저장) | 메모리 기반 (디스크 백업 가능) | AWS 인프라 기반 (클라우드 저장소 활용) | 메모리 기반 저장소 (휘발성 데이터 처리에 유리) |
| 메시지 순서 보장 | 파티션 단위에서 순서 보장 가능 | 큐 단위 순서 보장 (FIFO) |
표준 큐와 FIFO 큐 선택 가능 | 순서 보장 기본 제공하지 않음, 구현 필요 |
| 확장성 | 파티션 및 브로커 추가로 수평적 확장 용이 | 클러스터링 및 브로커 추가를 통해 확장 가능 | 자동 확장 가능 (AWS 인프라 활용) | 노드 추가를 통한 클러스터 확장 가능 |
| 프로토콜 | Kafka 전용 프로토콜 (TCP/IP 기반) | AMQP, STOMP, MQTT 등의 다중 프로토콜 지원 | AWS API (HTTP/HTTPS 방식) | Redis 자체 프로토콜 (TCP 기반) |
| 내결함성 | 복제 및 다중 브로커 구성을 통해 데이터 보호 | 클러스터링과 복제를 통한 내결함성 보장 | 다중 가용 영역으로 데이터 손실 방지 | 기본적으로 데이터 복제 및 클러스터링 가능 |
| 성능 특성 | 대용량 데이터 처리에 최적화, 높은 처리량 | 낮은 지연시간, 메시지 전송 속도 빠름 | 비용 효율적이고 확장 가능한 처리 용량 | 고속 데이터 접근 및 처리 속도, 지연시간 짧음 |
| 운영 및 관리 | 운영 및 클러스터 관리 필요 (분산 시스템 관리) | 설정 및 관리가 비교적 복잡할 수 있음 | 완전 관리형 서비스로 설정 및 관리 간소화 | 단순한 설정과 클러스터링 구성 가능 |
| 장점 | - 대용량 데이터 스트리밍에 최적화 - 높은 내구성 및 장애 복구 가능 |
- 다양한 메시지 패턴 지원 - 신뢰성이 높음 - 메시지 우선순위 지정 가능 |
- 완전 관리형으로 인프라 관리 필요 없음 - 유연한 스케일링 |
- 빠른 응답 속도 - 다양한 데이터 구조 지원 - Pub/Sub 기능 강력 |
| 단점 | - 초기 설정과 운영이 복잡할 수 있음 - 소규모 애플리케이션에는 과할 수 있음 |
- 설정이 복잡하고 성능 조정 필요 - 디스크 I/O에 의존적 |
- FIFO 큐 사용 시 처리 비용 증가 - API 호출 수에 따른 요금 발생 |
- 데이터가 휘발성으로 사라질 수 있음 - 메시지 순서 보장 어려움 |

'Develop Study > Middleware' 카테고리의 다른 글
| (24.10.17) NginX 정리 + 본인 프로젝트에서 활용한 부분 추가 (1) | 2024.10.17 |
|---|
