[Gena Co.] Internship Project/GENA Labeling Tool
(25.03.10) 데이터 CSV 파일 업로드 / 다운로드 요청 시의 컬럼 순서 문제
인턴십 기간 중 Labeling 데이터 및 CSV 로 정리된 AI 학습용 데이터의 일부분을 업데이트 Application 및 툴을 개발하는 과정에서,
파일을 다운로드 시 업로드 했을 때와 컬럼의 순서가 보장이 되지않아, AI 학습을 위한 정상적인 처리에 애로사항이 발생을 해 관련 내용을 해결하며 트러블슈팅을 정리하고자 한다.
이슈
- CSV 파일을 서버에 업로드시, MySQL DB에 데이터를 저장하여, Labeling Tool 을 통해 업로드된 정보로 최신화하여 다시 다운로드 기능의 트러블
- CSV 파일을 서버에 업로드시, MySQL DB 테이블의 해당 Sample Row Data를 sample_data 컬럼에 JSON 형태의 TEXT 로 저장하고자 할 때, 기존 CSV 파일의 컬럼의 순서가 보장이 안되는 현상 발생
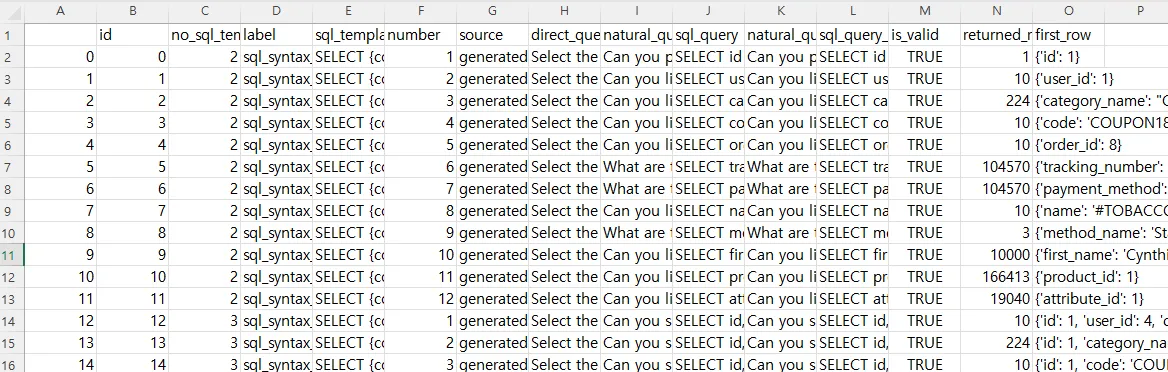
- Upload 할 CSV 파일의 Example
| id | no_sql_template | label | sql_template | number | source | direct_question | natural_question | sql_query | natural_question_edited | sql_query_edited | is_valid | returned_rows | first_row |
| 0 | 2 | sql_syntax_function | SELECT {column1:from_table1} FROM {table1}; | 1 | generated-rewritten | Select the id from the addresses table. | Can you provide the first ID from the addresses table? | SELECT id FROM addresses LIMIT 1; | Can you provide the first ID from the addresses table? | SELECT id FROM addresses LIMIT 1; | TRUE | 1 | {'id': 1} |
| 1 | 2 | sql_syntax_function | SELECT {column1:from_table1} FROM {table1}; | 2 | generated-rewritten | Select the user_id from the carts table. | Can you list the first 10 user IDs from the carts? | SELECT user_id FROM carts LIMIT 10; | Can you list the first 10 user IDs from the carts? | SELECT user_id FROM carts LIMIT 10; | TRUE | 10 | {'user_id': 1} |
| 2 | 2 | sql_syntax_function | SELECT {column1:from_table1} FROM {table1}; | 3 | generated-rewritten | Select the category_name from the categories table. | Can you list all the category names we have? | SELECT category_name FROM categories; | Can you list all the category names we have? | SELECT category_name FROM categories; | TRUE | 224 | {'category_name': "Children's"} |
| 3 | 2 | sql_syntax_function | SELECT {column1:from_table1} FROM {table1}; | 4 | generated-rewritten | Select the code from the coupons table. | Can you list all the coupon codes? | SELECT code FROM coupons; | Can you list all the coupon codes? | SELECT code FROM coupons; | TRUE | 10 | {'code': 'COUPON1835'} |
- Upload 요청 시의 Service Entity 클래스 와 Service 메서드
// Sample Entity
...
public class Sample extends Timestamp {
...
// JSON 타입의 TEXT 로 저장
@Column(columnDefinition = "JSON")
private String sampleData;
... // Upload 파일 요청 Service 메서드
@Transactional
public void uploadCsvFile(MultipartFile file, DatasetMetadataDto metadata) throws Exception {
String datasetName = metadata.getDatasetName();
String datasetDescription = metadata.getDatasetDescription();
// Controller 에서 받아온 file 을 읽으면서 처리
try (CSVReader csvReader = new CSVReader(new InputStreamReader(file.getInputStream()))) {
String[] columns = csvReader.readNext();
if (columns == null) throw new FileProcessingException("CSV file is empty");
Map<String, Integer> columnIndexMap = new HashMap<>();
for (int i = 0; i < columns.length; i++) {
for (DatasetColumn column : DatasetColumn.values()) {
if (columns[i].equalsIgnoreCase(column.toString())) {
columnIndexMap.put(column.toString(), i);
}
}
}
...
// 파일에서 읽어온 데이터를 Sample 엔터티로 만든후 저장
while ((nextRecord = csvReader.readNext()) != null) {
JsonObject sampleData = new JsonObject();
for (int i = 0; i < columns.length; i++) {
sampleData.addProperty(columns[i], nextRecord[i]);
}
Sample sample = Sample.builder()
.id(UUID.randomUUID().toString())
.datasetName(datasetName)
.datasetDescription(datasetDescription)
.versionId(1L)
.status(SampleStatus.CREATED)
.sampleData(sampleData.toString())
.build();
sampleList.add(sample);
...
}
}
sampleRepository.saveAll(sampleList);
} catch (Exception e) {
throw new FileUploadException(e.getMessage(), e);
}
}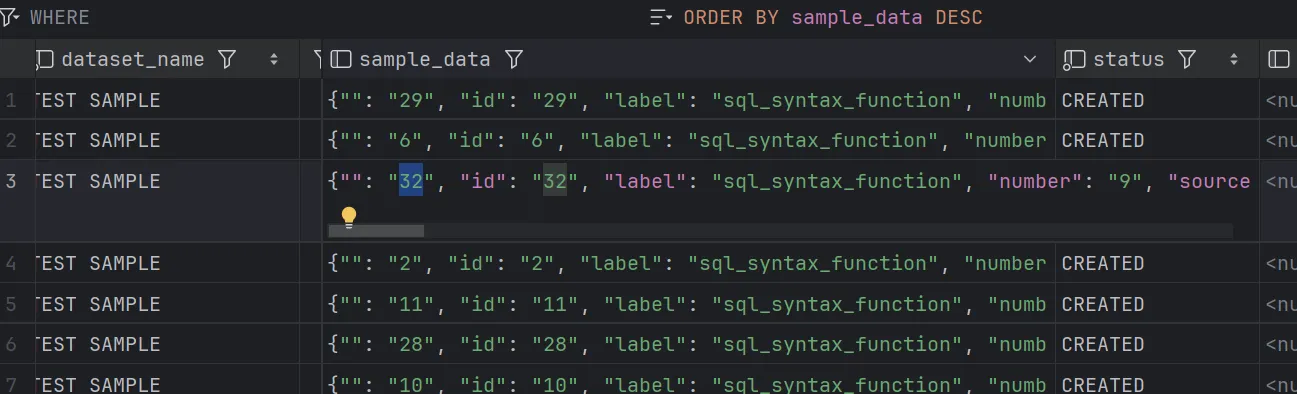
id, label, number, source, is_valid, first_row, sql_query, sql_template, returned_rows, direct_question, no_sql_template, natural_question, sql_query_edited, natural_question_edited
- sample_data 에 저장되는 CSV 로우 데이터가 매번 업로드 시 컬럼 순서가 섞여버린 상태 → 해당 값을 기준으로 다운로드 될 때 해당 섞인 컬럼 순서에 맞춰서 순서대로 CSV 파일로 응답하기 때문에, Upload / Download 컬럼 순서가 달라지는 현상
원인
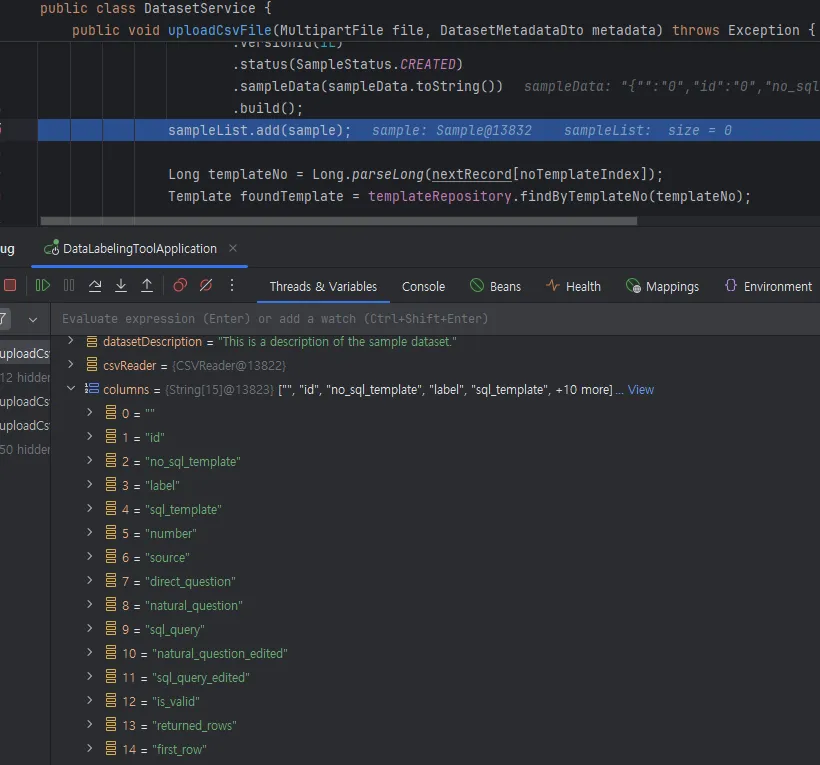
- log를 사용했을 때, Service 에서 MySQL DB 로 저장되기 직전에 생성된 sample 객체에서는 정상 적으로 위의 Example의 CSV 에서 순서대로 저장하고 있음을 debug 로 확인
- 즉 JSON 형태로 MySQL DB 에 저장되는 과정중에 컬럼의 순서가 보장되지 않고 섞여버리게 된 것
- JSON 자체는 key-value 의 pair 형태를 저장하는 일종의 HashMap 데이터 구조로써 Java Jackson = Java의 JSON 라이브러리 기준으로 순서를 보장하지 않기 때문에, DB 테이블에 데이터를 저장하는 과정에서 순서를 보장할 수가 없는 것으로 파악
해결
// Sample Entity
...
public class Sample extends Timestamp {
...
// JSON 타입의 TEXT 로 저장
@Column(columnDefinition = "LONGTEXT")
private String sampleData;
...- Sample 로우 데이터 → Java 가 JSON 형태 JsonObject 객체로 변환 → 해당 객체를 toSpring() 메서드를 통해 TEXT 형태화 한 뒤, Sample 객체를 생성 → 그대로 save 를 통해 DB에 저장 과정 중 JsonObject 객체로 저장 하는 과정에서 문제가 발생하는 것으로 판단
- JSON 으로 저장을 하는 것이 아닌 TEXT(LONGTEXT) 로 문자 그대로를 저장하는 방향으로 변경
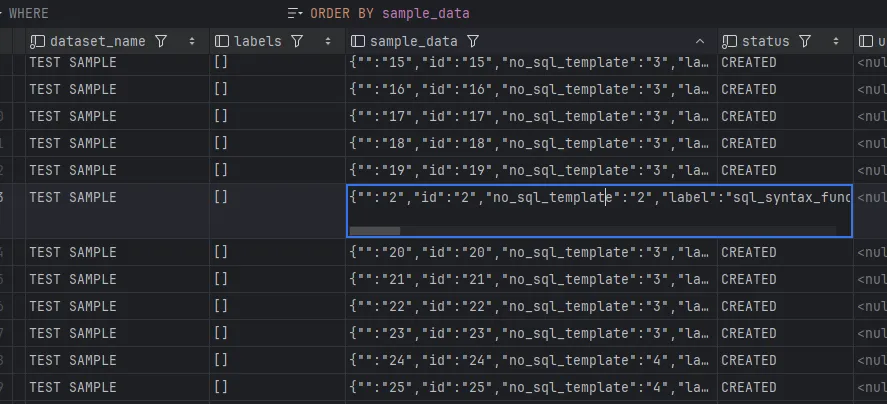
@Transactional
public InputStreamResource getCsvFile(String datasetName) {
...
for (Sample sample : samples) {
JsonObject sampleData = JsonParser.parseString(sample.getSampleData()).getAsJsonObject();
String[] row = Arrays.stream(headers)
.map(header -> sampleData.has(header) ? sampleData.get(header).getAsString() : "")
.toArray(String[]::new);
csvWriter.writeNext(row);
}
...- 반대로 Download시, JsonParser 를 통해서 JSON 형태로 바꿔 key-value 중 특정 value를 최신화 시킬 수 있도록 로직이 따라서 변경이 되었음
JsonObject 객체가 JSON 형태과 구별되어서 착각했기 때문에, 가장 먼저 시도한 것은 Map 기반의 자료형태를 LinkedHashMap 자료구조를 채택해서 순서를 보장하려고 했지만 역시 디버깅 과정에서 굳이 자료구조를 변경하지 않더라도 정상적으로 Map->JsonObject 가 진행되었기에 해당 내용은 생략했다.
MySQL 이 지원하는 포맷은 많지만, JSON 이더라도 JPA 를 통한 저장에서는 String 타입으로 저장되기 때문에
해당 형태(위에서는 JSON)로 변환이 DB에서 이뤄진 후 저장이 된다.
따라서, 자료를 정교하게 JPA를 통해서 다루긴 위해서는 JSON 필드의 순서든지 더 정교하고 일관된 자료를 다루긴 위해서 위 트러블 슈팅처럼 TEXT 자체로 활용하고 Service 에서 해당 파일로 변환 또는 Converter 작업등이 미리 이뤄져야할 것이다.

'[Gena Co.] Internship Project > GENA Labeling Tool' 카테고리의 다른 글
| (25.03.14) Docker Compose 설정 & Swagger 세팅 (0) | 2025.03.18 |
|---|---|
| (25.03.11) Event Sourcing Refactoring (0) | 2025.03.18 |
| (25.03.05) Label CRUD & CSV File Download 기능 구현 (0) | 2025.03.06 |
| (25.03.01) ERD Update & 기능 개발(User, Sample, Template, Group CRUD) (0) | 2025.03.05 |
| (25.02.26) ERD - Simplified (0) | 2025.02.26 |



